AIを使った画像認識の紹介と活用

はじめに
この記事では、画像を扱うAIは何が可能なのか、そのAIがどのように活用されているのか、これからどのように活用されていきそうなのかという点をタスクごとに手法を交えて紹介していきます。
この記事でAIに興味を持っていただき、またどのようなことが出来るか知ってもらえたら幸いです。
AIとは
Artificial Intelligence(AI)は日本語にすると「人工知能」と訳されます。
AIの定義は知性や知能自体に定義がないため、一概に定義することは困難であり、人により捉え方が異なります。
そこで、本記事ではAIを機械学習分野の一部であるDeepLearningの手法として定義した上で説明をしていきたいと思います。
DeepLearningとは
手法の話をする前に簡単にDeepLearningとはどのようなものなのかを説明します。
DeepLearningとは、Deep Neural Network(DNN)により多量なデータから正解を導き出す「特徴」を学習する機械学習の手法です。
ここでいう「特徴」というのは、犬を例に出すと「しっぽがあり、鼻が長くて4足歩行が多くて...」といった、画像から見て分かる外見上の犬らしさのことです。この「特徴」を学習することで学習データに含まれない犬種の画像を、AIに与えても犬と識別することができます。
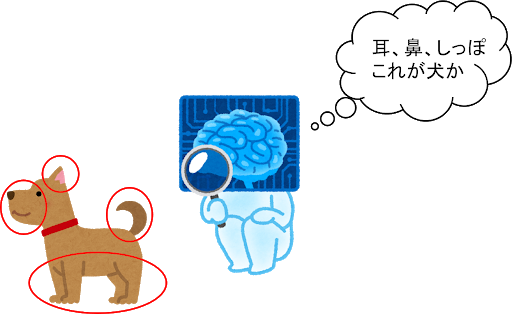
画像を用いたDeepLearningのタスク
本題に入り、タイトルにもある画像を扱うAIはいったい何ができるのかという話ですが、画像分野だけでもたくさんあり、この記事でも一部しか触れることができません。
そのため本記事では画像分野でよく取り扱われる物体認識、物体検出、セグメンテーション、画像生成、姿勢推定のタスクに絞って説明します。
以下では、それぞれのタスクが何をしていてどのような活用方法があるか説明していきます。これらの分野では多くの論文が発表されており、以下でも具体的な手法名を記載していますので、もっと詳しく知りたい方は各手法名を手がかかりに論文等を調べていただけるとより理解が深まると思います。
物体認識(Object recognition)
「物体認識」は、入力した画像が何の画像であるか認識するタスクになります。
「物体認識」は、製造現場の検品で良品か不良品かの識別に使われたり、撮影した画像を風景、動物、人物のように自動でフォルダ分けして見やすくしたりといった点で実際に活用されています。
また「DeepLearningとは」の項では犬のみでしたが、実際は複数のクラスを同時に学習することができます。AIが画像の「特徴」を抽出してそれぞれのクラスが何%くらいの割合であるかを示します。例えばこの図では犬の画像を入力して犬が70%、オオカミが28%、猫が2%となり犬が正解だとAIは推定しています。この図のAIは犬、オオカミ、猫の3クラスを学習したものになっており、3クラスの合計が100%になるように確率を出力します。
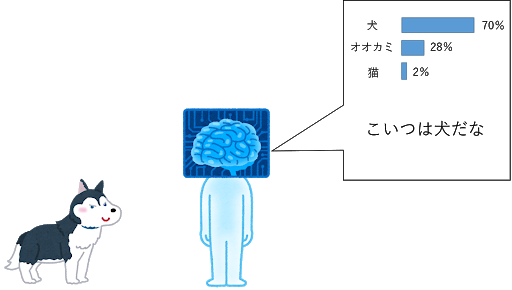
物体認識の手法にはVGG[1]、ResNet[2]、EfficientNet[3]等があります。
VGG<ResNet<EfficientNetの順に複雑化していき処理に時間がかかる代わりに高精度な手法になっています。
物体検出(Object detection)
「物体認識」では与えた画像が何であるかというタスクでしたが、「物体検出」は図のように画像中の物体の位置を得るタスクになっています。

このタスクは、検品時に欠陥がどこにあるか見つける、会場への入場者が何人いるか数える、歩行者の検出[4]などの活用方法があります。また、医療分野でも医者の補助として胃カメラやCT画像等の医療画像から疾病箇所を検出する試みもあります。
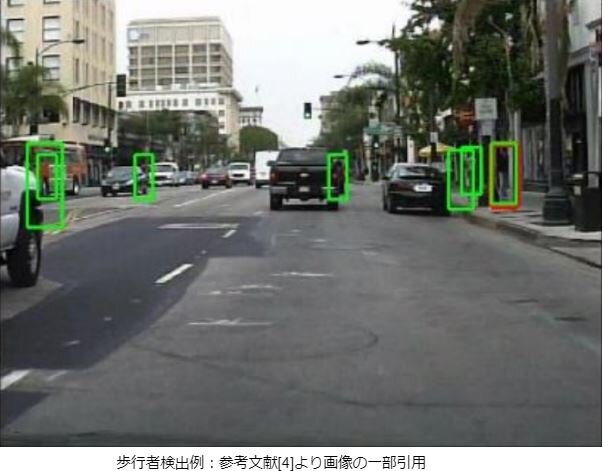

物体検出手法としてFaster-RCNN[5]、Single Shot Detector(SSD)[6]、You Look Only Once(YOLO)[7]があります。
Faster-RCNNはRPNと呼ばれる部分で「物体検出」を行ったのち、検出領域に対して「物体認識」を行う手法になっています。SSD、YOLOは検出と認識を同時に行う構造になっています。
セグメンテーション(Segmentation)
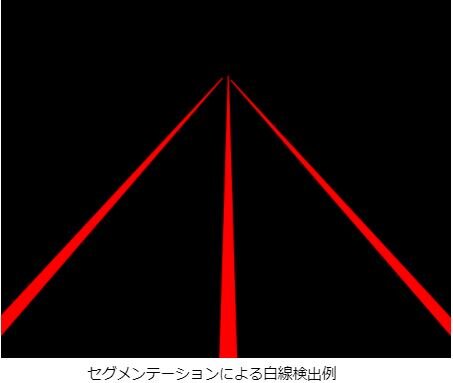
「物体認識」が画像単位、「物体検出」が物体領域単位と説明してきましたが、「セグメンテーション」は図のように画素単位で分類を行う手法です。

「物体検出」は物体領域を矩形で囲むように答えを得ていましたが、「セグメンテーション」は画素単位なのでより細かく物体領域を分割することが可能です。
活用例としては、壁やパイプの亀裂の検出や道路の白線認識があります。
これらを「物体検出」で行うと図のように1つの大きな矩形や小さい複数の矩形で検出されてしまうため、「物体検出」手法より「セグメンテーション」手法を使う方が向いている例になります。
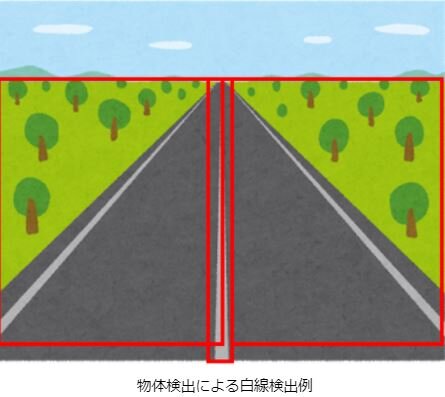
また、「セグメンテーション」のタスクには「セマンティックセグメンテーション」と「インスタンスセグメンテーション」があります。
「セマンティックセグメンテーション」は、画素単位で分類を行うタスクであり上記で説明したものになります。しかしながら同じ物体が重なっていた場合、1つの領域になってしまい、それらを分割することができません。一方で「インスタンスセグメンテーション」は重なった同物体の境界を認識して分割できる手法となっています。
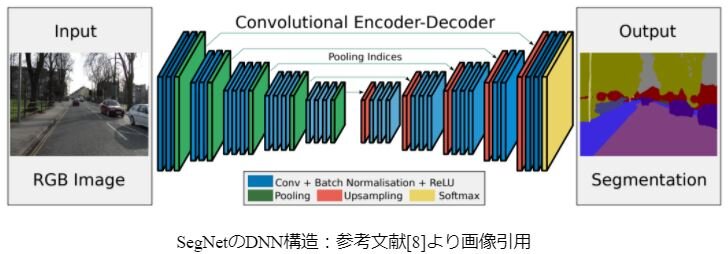
「セマンティックセグメンテーション」の手法には、SegNet[8]、UNet[9]等があり、「インスタンスセグメンテーション」の手法には、SSAP[10]等があります。
セグメンテーションのDNN構造の特徴としては畳み込み処理により解像度を下げてからもとのサイズに戻すエンコーダー・デコーダー構造になっている点です。これにより入力サイズと同じサイズの画像となり画素単位の分類が可能になります。
画像生成(Image generation)
ここまでは認識や検出といった「分類する」、「見つける」タスクでしたが、「画像生成」はその名の通り「画像の生成」を目標にするタスクになっています。
「画像生成」分野の初期ではDCGAN[11]、VAE[12]のような低い解像度でしたが近年ではStyleGAN[13]やVQ-VAE-2[14]等の高解像度の手法が提案され本物と区別ができないレベルに達しています。

「画像生成」の応用例は、他のタスクに使用する学習データの生成があります。
「物体認識」や「物体検出」のタスクには多量のデータが必要不可欠です。
しかしながら欠陥の検出や認識をするAIの場合、欠陥品の収集、撮影、ラベル付けとデータの容易に時間を要し欠陥が現れるまで待つ必要があります。そこで画像生成AIにより欠陥画像を生成できれば外観検査機のAIを短期間で高精度なものにできる見込みがあります。
姿勢推定(Pose estimation)
「姿勢推定」は人や物体の姿勢を推定するタスクになります。
例えば、人を対象とした「姿勢推定」は、人の骨格を推定することで動きのトラッキングに使用されます。
近年だとバーチャル世界(仮想世界)で自分のアバターを自分の体の動きで操作するといったことが行われているため、リアルタイムで高精度な「姿勢推定」能力が求められます。また投げる、持ち上げるといった動作の認識にも「姿勢推定」の力が必要になります。
物体の姿勢推定の分野では、物体がどの姿勢で置かれているか認識することでロボットがものを掴んで正しい姿勢で置き直すこと、などが可能となっています。

人の「姿勢推定」手法にはOpenPose[15]、UniPose[16]等、物体の「姿勢推定」の手法にはSSD6D[17]、PVNet[18]等があります。
まとめ
本記事では画像を用いたAIにより何が出来るか何に活用できるかを実際の手法名を出しつつ紹介しました。
我々MusashiAIでも画像を用いたAIにより欠陥の検出や認識を行う検査機の作成に取り組んでいます。
そしてAIにより従来の画像処理では検出困難な欠陥を見つけられるようになり外観検査を行う現場の人の負担を減らすことが可能になりました。
今後も努力とAIの発展により更に高精度、高速化されると考えられます。
参考文献
- Karen Simonyan, et al., ‘VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION ’, ICLR, 2015.
- Kaiming He, et al., ‘Deep Residual Learning for Image Recognition’, CVPR, 2016.
- Mingxing Tan, et al., ‘EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks’, ICML, 2019.
- Piotr Dollar, et al., ‘Pedestrian Detection: An Evaluation of the State of the Art’, PAMI, 2012.
- Shaoqing Ren, et al., ‘Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks’, NIPS, 2015.
- Wei Liu, et al., ‘SSD: Single Shot MultiBox Detector’, ECCV, 2016.
- Jpseph Redmon, et al., ‘You Only Look Once: Unified, Real-Time Object Detection’, CVPR, 2016.
- Vijay Badrinarayanan, et al., ‘SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation’, PAMI, 2017.
- Olaf Ronneberger, et al., ‘U-Net: Convolutional Networks for Biomedical Image Segmentation’, MICCAI, 2015.
- Naiyu Gao, et al., ‘SSAP: Single-Shot Instance Segmentation With Affinity Pyramid’, ICCV, 2019.
- Alec Radford, et al., ‘Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks’, ICRA, 2016.
- Diederik P Kingma, et al., ‘Auto-Encoding Variational Bayes’, ICLR, 2014.
- Tero Karras, et al., ‘A Style-Based Generator Architecture for Generative Adversarial Networks’, CVPR, 2019.
- Ali Razavi, et al., ‘Generating Diverse High-Fidelity Images with VQ-VAE-2’, NIPS, 2019.
- Zhe Cao, et al., ‘OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields’, CVPR, 2017.
- Bruno Artacho, et al., ‘UniPose: Unified Human Pose Estimation in Single Images and Videos’, CVPR 2020.
- Wadim Kehl, et al., ‘SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again’, ICCV, 2017.
- Sida Peng, et al., ‘PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation’, CVPR, 2019.